Cách xây dựng một mạng Nơ-ron đơn giản chỉ bằng Python
H
Welcome to my blog. I'm Duy Hieu, Senior Software Engineer at Integro Lending (Singapore). I created this blog to share my stories.
Search for a command to run...
No comments yet. Be the first to comment.
1. Sạch Phải công nhận là Sing sạch, đi đâu cũng thấy có người đang quét dọn, tỉa cành, gom rác, cắt cỏ,… Chi phí để duy trì môi trường cảnh quan chắc cũng không hề nhỏ. 2. Giao thông công cộng Bên này chủ yếu đi bằng tàu điện (MRT) và xe bus, chi ph...
In the previous article, I covered the basic concepts and introduced a 5-step process for applying DDD in practice. Today, I will bring you a bigger challenge. In this article, we will work through an

I. Why DDD matters? A Bigger Picture Over the years, as business needs have grown increasingly complex, our application systems have evolved - from monoliths to SOA, and now to microservices. This evolution demands a rational approach to component de...

Behind every robust software system lies a suite of well-structured unit tests. But what defines a great unit test? In this article, we’ll examine its anatomy and best practices to ensure your tests are both reliable and effective. I. A Bigger Pictur...

This is a nice feedback from my Singaporean Scrum Master for 2024. According to Vietnamese beliefs, 2024 marked the final year of a challenging three-year period (Tam Tai) for those born in 1996, a time filled with uncertainties and difficulties. Al...
Bài viết được dịch lại từ bài How to build your own Neural Network from scratch in Python link. Bài viết này hiện được 44k up vote từ cộng đồng 😘😘😘
Motivation: Là một phần trong hành trình cá nhân của tôi để hiểu rõ hơn về Deep Learning, tôi đã quyết định xây dựng Mạng lưới thần kinh từ đầu mà không cần thư viện học sâu như TensorFlow. Tôi tin rằng việc hiểu được hoạt động bên trong của Mạng thần kinh là điều quan trọng đối với bất kỳ Nhà khoa học dữ liệu nào.
Bài viết này chứa những gì tôi đã học và hy vọng nó cũng sẽ hữu ích cho bạn!
Hầu hết các văn bản giới thiệu về Mạng nơ-ron đưa ra các mô tả giống bộ não của con người. Không đi sâu vào các cách này, tôi thấy dễ dàng hơn khi mô tả Mạng thần kinh là một hàm toán học ánh xạ một đầu vào nhất định đến một đầu ra mong muốn.
Mạng nơ-ron bao gồm các thành phần sau:
Sơ đồ bên dưới hiển thị kiến trúc của Mạng nơ-ron 2 lớp (lưu ý rằng lớp đầu vào thường bị loại trừ khi đếm số lớp trong Mạng nơ-ron)
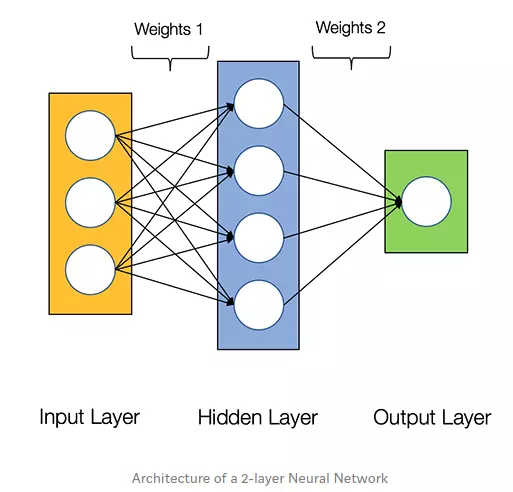
Tạo một lớp Mạng Nơ-ron với Python thật dễ dàng !!!
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(y.shape)
Đầu ra ŷ của Mạng nơ ron 2 lớp đơn giản là:
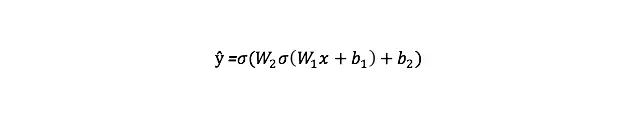
Bạn có thể nhận thấy rằng trong phương trình trên, trọng số W và độ lệch b là các biến duy nhất ảnh hưởng đến đầu ra ŷ.
Đương nhiên, các giá trị phù hợp cho các trọng số và độ lệch quyết định độ chính xác của các dự đoán. Quá trình tinh chỉnh các trọng số và độ lệch từ dữ liệu đầu vào được gọi là huấn luyện mạng Nơ-ron.
Mỗi lần lặp của quá trình đào tạo bao gồm các bước sau:
Biểu đồ tuần tự dưới đây minh họa quá trình.

Như chúng ta đã thấy trong biểu đồ tuần tự ở trên, feedforward chỉ là phép tính đơn giản và đối với mạng thần kinh 2 lớp cơ bản, đầu ra của Mạng thần kinh là:
Hãy thêm một hàm feedforward trong mã python để làm điều đó. Lưu ý rằng để đơn giản, chúng ta đã giả sử các độ lệch là 0.
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
Tuy nhiên, chúng ta vẫn cần một thứ gì đó để đánh giá "mức độ tốt" của các dự đoán của chúng ta (tức là dự đoán có giống với đầu ra mong muốn không)? Hàm mất mát cho phép chúng ta làm chính xác điều đó.
Có rất nhiều loss function có sẵn, và bản chất vấn đề của chúng ta nên quyết định lựa chọn loại hàm nào. Trong hướng dẫn này, chúng ta sẽ sử dụng hàm sum-of-squares error là hàm mất mát của chúng tôi.

Nghĩa là, lỗi tổng bình phương chỉ đơn giản là tổng của sự khác biệt giữa mỗi giá trị dự đoán và giá trị thực tế. Sự khác biệt là bình phương để chúng ta đo giá trị tuyệt đối của sự khác biệt.
Mục tiêu của chúng ta trong huấn luyện là tìm ra tập hợp trọng số và độ lệch tốt nhất giúp giảm thiểu loss function.
Bây giờ chúng tôi đã đo được lỗi dự đoán (mất), chúng tôi cần tìm cách truyền lại lỗi và cập nhật các trọng số và sai lệch của chúng tôi.
Để có thể điều chỉnh trọng số và độ lệch một cách thích hợp, chúng ta cần biết đạo hàm của hàm mất mát đối với các trọng số và độ lệch.
Nhớ lại từ phép tính rằng đạo hàm của hàm đơn giản là độ dốc của hàm.
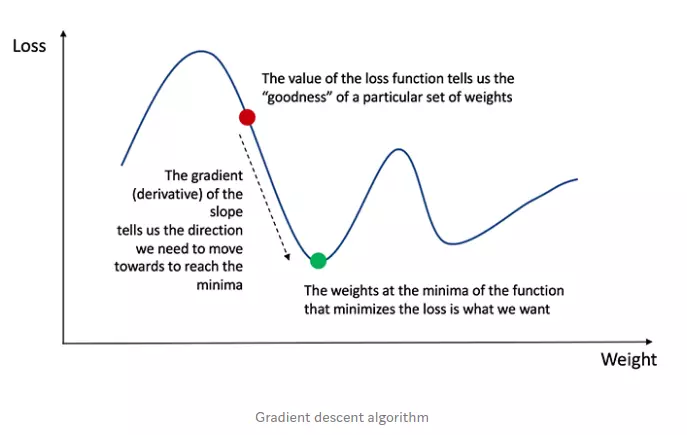
Nếu chúng ta có đạo hàm, chúng ta chỉ cần cập nhật các trọng số và độ lệch bằng cách tăng/giảm với nó (tham khảo sơ đồ trên). Điều này được gọi là độ dốc gốc.
Tuy nhiên, chúng ta có thể trực tiếp tính toán đạo hàm của hàm mất mát đối với trọng số và độ lệch vì phương trình của hàm mất mát không chứa trọng số và độ lệch. Do đó, chúng ta cần quy tắc chuỗi để giúp chúng ta tính toán nó.

Ái chà! Điều đó thật xấu xí nhưng nó cho phép chúng ta có được những gì chúng ta cần - đạo hàm (độ dốc) của hàm mất mát đối với các trọng số, để chúng ta có thể điều chỉnh các trọng số cho phù hợp.
Bây giờ chúng ta hãy thêm chức năng backpropagation vào mã python của chúng ta.
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
def backprop(self):
# application of the chain rule to find derivative of the loss function with respect to weights2 and weights1
d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) * sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1)))
# update the weights with the derivative (slope) of the loss function
self.weights1 += d_weights1
self.weights2 += d_weights2
Để hiểu sâu hơn về ứng dụng tính toán và quy tắc chuỗi trong backpropagation, tôi thực sự khuyên bạn nên xem hướng dẫn này của 3Blue1Brown.
{@embed: https://www.youtube.com/watch?v=tIeHLnjs5U8}
Bây giờ chúng ta đã có mã python hoàn chỉnh để thực hiện feedforward và backpropagation, hãy để ứng dụng Mạng nơ-ron của chúng ta vào một ví dụ và xem nó hoạt động tốt như thế nào. Bên dưới là dữ liệu huấn luyện đơn giản:
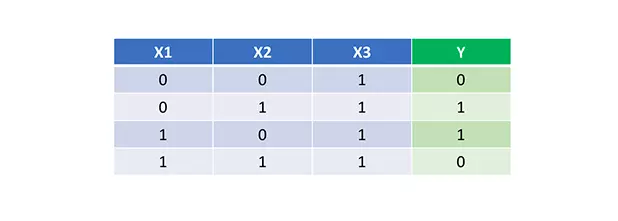
Mạng nơ-ron của chúng ta sẽ học một tập hợp trọng số lý tưởng để biểu diễn được hàm này. Thường thì chúng ta sẽ cho dừng việc học khi ta xấp xỉ được hàm để tránh vấn đề overfit.
Hãy huấn luyện Mạng nơ-ron với 1500 lần lặp và xem điều gì sẽ xảy ra. Nhìn vào biểu đồ biểu diễn hàm mất mát trên mỗi lần lặp bên dưới, chúng ta có thể thấy rõ sự mất mát đơn điệu giảm dần về mức tối thiểu. Điều này phù hợp với thuật toán giảm độ dốc mà chúng ta đã thảo luận trước đó.
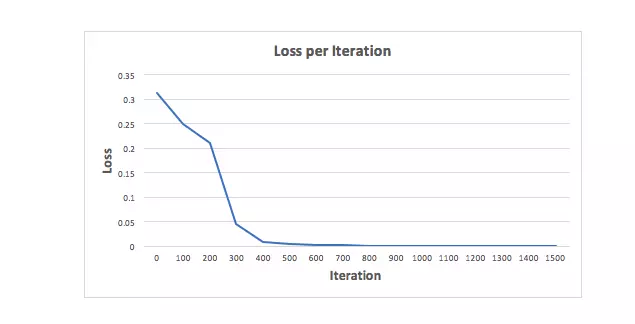
Chúng ta hãy xem dự đoán cuối cùng (đầu ra) từ Mạng nơ-ron sau 1500 lần lặp.
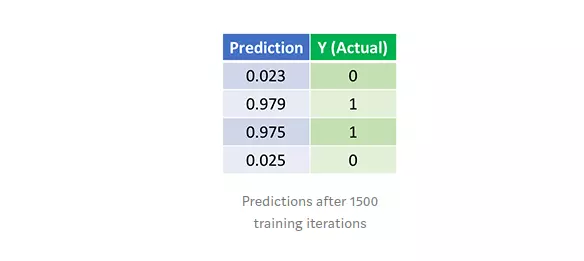
Done =)) Thuật toán feedforward và backpropagation của chúng tôi đã đào tạo một mạng nơ-ron thành công và các dự đoán được hội tụ trên các giá trị thực.
Lưu ý rằng có một sự khác biệt nhỏ giữa dự đoán và giá trị thực tế. Điều này là cần thiết, vì nó tránh việc mô hình bị overfitting và cho phép Mạng nơ-ron dự đoán tốt hơn với dữ liệu mới.
Hành trình của chúng ta vẫn chưa kết thúc. Vẫn còn nhiều điều để tìm hiểu về Mạng nơ-ron và Học sâu (Deep Learning). Ví dụ:
Tôi đã học được rất nhiều điều khi viết Mạng nơ-ron từ đầu chỉ với Python mà không dùng bất cứ thư viện có sẵn nào.
Mặc dù các thư viện Deep Learning như TensorFlow và Keras giúp ta dễ dàng xây dựng các mạng lưới sâu mà không hiểu đầy đủ hoạt động bên trong của Mạng nơ-ron, nhưng tôi thấy rằng việc xây dựng lại có lợi cho các nhà khoa học dữ liệu đang khao khát hiểu sâu hơn về Mạng nơ-ron.
This exercise has been a great investment of my time, and I hope that it’ll be useful for you as well!