High Performance in MySQL - Part 1

MySQL is an open-source relational database management system and is one of the most common databases. Everyone uses MySQL and me too. But whether we are using it correctly and optimally.
Today I will share my experience and what I learned in 3 main topics: Schema Design, Indexing and Query Optimization.
But before we dig dive into them, we should understand MySQL's logical architecture. In other words, we should understand how MySQL processes our queries.
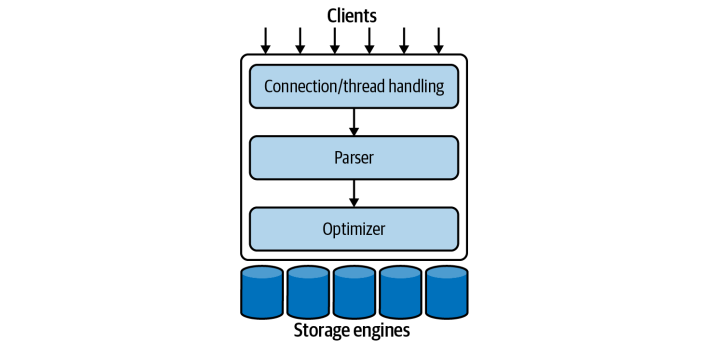
When we send a query to MySQL:
- MySQL will check and open connection (reject if too many connections)
- Parser will parse the query to check the syntax
- Optimizer will optimize the query (based on Performance Schema)
- Run the optimized query
And you see, MySQL will optimize our queries depending on metrics in the Performance Schema before running them. So which data types we use, how we design our tables, how we do the indexing and how we write the queries, will determine the performance of our database. It's hard to read and remember all knowledge so I write it as a quick note with multiple points. Anw, let's start!
I. Schema Design
1. Data Types
Using optimal data types not only reduces the storage space but also improves the query performance (because query data will be loaded onto RAM => if RAM is full, data will be flushed to disk => poor performance)
- Smaller is usually better
- Simple is good (e.g, use decimal rather than string for lat/long values)
- Avoid null if possible: harder for MySQL to optimize queries
Let's check the data types MySQL has and discuss when we should use them:
Varchar: variable length
use 1 or 2 extra bytes to store length, 1 byte if the value requires no more than 255 bytes, and 2 bytes if it’s more
Ex: varchar(10) will use up to 11 bytes, varchar(500) will use up to 502 bytes
- Should use varchar(255) to maximize the use of a column because it needs only 1 extra byte for length.
- Char: fixed length of characters => good choice for storing hashed user password
- Text: string data types designed to store large amounts of data, cannot index full length. It will be stored off the table when the value is greater than 8kb and needs to be read from the disk when querying.
- Blob: store binary data (images, videos,...) => in practice, we should save images and videos in other storage space and store image paths in MySQL (avoid full RAM)
- Integer: tinyint 1 byte, small int 2 bytes, int 4 bytes, bigint 8 bytes => the width for integer types such as int(11) which is meaningless for most applications because it does not restrict the range of values
- Real number: Float 4 bytes, Double 8 bytes. Double has greater precision than Float
- Datetime: 1000 - 9999, 8 bytes
- Timestamp: 4 bytes, range 1970-2038, timestamp values will be converted from the current time zone to UTC for storage, and converted back from UTC to the current time zone for retrieval
- Decimal: store numbers with fractional part (e.g, financial data)
- Enum: cannot update value orders in enum, will be stored as int (should use tinyint instead so that you do not need to alter)
Notes: with varchar, text type, we should create a prefixed index if needed.
2. Schema Design Mistakes
- Too many columns: heavy bin log could lead to replication lag, poor performance when pulling data onto memory for read/join queries,...
- Too many joins: should join on 3 tables at most (harder for query optimization)
- Should not use null
II. Indexing
The index is a data structure that storage engines use to find rows quickly. Index performance can drop very quickly when our dataset grows.
1. Types of Indexes
a. B-tree indexes
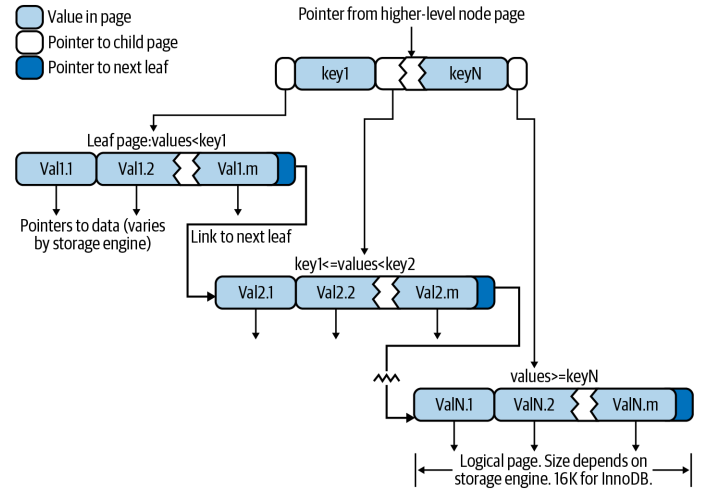
- A data structure that store data in its node in sorted order
- Leaf pages contain a link to the next for fast range traversals through nodes (has order)
- Leaf pages have pointers to the indexed data
- Storage engine does not have to scan the whole table to find the desired data
Advantages
- B-trees store indexed columns in order => useful for range searching
- Work well for lookups by the full key value, a key range, a key prefix
- Store replated values close together
- Index stores a copy of values => some queries can be satisfied from the index alone (covering index)
=> Index reduces the amount of data the server has to examine
=> Index helps the server avoid sorting and temporary tables
Limitation
- Can’t skip columns in the index
Can’t optimize accesses with any columns to the right of the first range condition
VD: where last_name = “Smith” and first_name like ‘J%’ and dob = …. Because the LIKE is a range condition so MySQL cannot apply index for **dob** column searching.
Btree works with the following kinds of queries:
- Match on the full key value specifies values for all columns in the index
- Match a leftmost prefix: uses only the first column in the index
- Match a column prefix: uses only the first column in the index.
- Match one part exactly and match a range on another part
- Index-only queries: access only the index, not the row storage
b. Hash indexes
Hash indexes use hash tables to store data and have somewhat different characteristics from those just discussed:
They are used only for equality comparisons that use the = or != operators (but are very fast). They are not used for comparison operators such as < that find a range of values. Systems that rely on this type of single-value lookup are known as “key-value stores”; to use MySQL for such applications, use hash indexes wherever possible.
The optimizer cannot use a hash index to speed up ORDER BY operations. (This type of index cannot be used to search for the next entry in order.)
MySQL cannot determine approximately how many rows there are between two values (this is used by the range optimizer to decide which index to use).
Only whole keys can be used to search for a row. (With a B-tree index, any leftmost prefix of the key can be used to find rows.)
c. Adaptive Hash indexes
The InnoDB storage engine has a special feature called adaptive hash indexes. When InnoDB notices that some index values are being accessed very frequently, it builds a hash index for them in memory on top of B-tree indexes. This gives its B-tree indexes some properties of hash indexes, such as very fast hashed lookups. This process is completely automatic, and you can’t control or configure it, although you can disable the adaptive hash index altogether.
2. Indexing Strategies
a. Prefix
- Selectivity: ratio of the number of distinctly indexed values to the total number of rows in the table => higher is better
- With varchar /Text column: must define prefix indexes => long enough to give good selectivity and short enough to save space
- Cannot use prefix indexes for ORDER BY or GROUP BY queries, nor can it use them as covering indexes
b. MultiColumn indexes
- You need a single index with all relevant columns (AND), not multiple indexes that have to be combined
- OR condition: sometimes use lots of CPU and memory resources to merge
- Choose the most selective columns first in the index (examine the distribution of values in the table, count distinct / count *)
c. Clustered Indexes
- Store the Btree index and the rows together in the same structure
- When a table has a clustered index, its rows are actually stored in the index’s leaf pages
d. Secondary Indexes
- Secondary index accesses require two index lookups instead of one
- A leaf node doesn’t store a pointer to the referenced row’s physical location; rather, it stores the row’s primary key values
- To find a row from a secondary index, the storage engine first finds the leaf node in the secondary index and then uses the primary key values stored there to navigate the primary key and find the row (traverse two Btrees)
e. Covering Indexes
- An index that contains all data needed for a query is called a covering index
- Databases do not need to access the filesystem
III. Query Optimization
1. Optimize Data Access
a. Are You Asking the Database for Data You Don’t Need?
You should find out whether your application is retrieving more data than you need
- Fetching more rows than needed => need limit
- Fetching all columns from a multi-table join => define what columns you need
- Fetching all columns=> cannot use covering indexes, add more IO, memory
- Avoid using select * from
- But in some cases, we should query full objects, cache them, and use them many times could increase performance
- Fetching the same data repeatedly => caching
b. Is MySQL Examining Too Much Data?
In MySQL, the simplest query cost metrics are:
- Response time: Service time + Queue time
- Number of rows examined
- Number of rows returned
Ideally, the number of rows examined would be the same as the number returned (100%). To reduce the number of examined rows:
- Use covering indexes: no need to retrieve rows from tables
- Change the schema, using summary tables (prepare summary/report tables in advance)
- Rewrite a complicated query so the MySQL optimizer is able to execute it optimally
2. Ways to Restructure Queries
a. Complex Queries Versus Many Queries
The traditional approach to database design emphasizes doing as much work as possible with as few queries as possible. This approach was historically better because of the cost of network communication and the overhead of the query parsing and optimization stages.
However, this advice doesn’t apply as much to MySQL because it was designed to handle connecting and disconnecting very efficiently and to respond to small, simple queries very quickly. Modern networks are also significantly faster than they used to be, reducing network latency. So running multiple queries isn’t necessarily such a bad thing.
It’s still a good idea to use as few queries as possible, but sometimes you can make a query more efficient by decomposing it and executing a few simple queries instead of one complex one.
b. Chopping up a query
Need to delete old data => chop up a DELETE statement and run sequentially
E.g: DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH); => we will limit the number of affected rows: DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH) LIMIT 10000
=> minimize the impact on the server (smaller transactions), reduce replication lag
=> it might be a good idea to add some sleep time between DELETE statements to reduce the load on servers.
c. Join Decomposition
- MySQL can run well over 100000 simple queries per second
- Moderns networks are also significantly faster than they used to be
=> sometimes you can make a query more efficient by decomposing it and executing a few simple queries instead of one complex one.
Advantages
- Caching can be more efficient
- Reduce lock contention
- Doing joins in the application makes it easier to scale the database by placing tables on different servers (because we do not need to join)
- The queries themselves can be more efficient (such as using an IN() instead of a join lets MySQL retrieve rows more optimally)
- You can reduce redundant row accesses. Doing a join in the application means you retrieve each row only once, whereas a join in the query is essentially a denormalization that might repeatedly access the same data
Disadvantages
- Need to perform the join in the application
- Require a certain level of your team
IV. Conclusion
Phewww, we've just discussed about 3 main and most important topics in MySQL. I can not show all my experience and knowledge about MySQL in one post, so this post is like a note for me or anyone else to review and recall tips and strategies to improve MySQL performance.
In the next post, we will discuss Replication and Scaling techniques in MySQL. I will share how I scaled my database and improved read/write performance.
See you next time!


