Database Indexing - Data Structures & Supported Queries

I will tell you a fact that
Most of the hard issues come from databases when your system grows.
The bigger your system, the harder your database issues. Index, schema design, partition, and replication,... are important techniques to work with databases.
In particular, mastering indexing is a MUST for backend engineers.
I. Introduction
Indexes are data structures that storage engines use to find rows quickly. This is the most powerful way to improve query performance.

Store in a separate space with source data
Index Creation does not change the source data
Databases create a copy of the column that we create index and link to the original data
Index is implemented at storage engine layer
Each database, storage engine supports different index types
A backend engineer needs to master database indexing, or someday they headaches with database issues when their system grows x5 x10.
Benefits
Improve the search performance of SELECT
Reduce server’s workload and I/O of disk
Notes: Index also works for UPDATE queries with WHERE when using indexes to look up the record and update
E.g. UPDATE … WHERE id = 1
Limitation
More space for index (disk, memory)
INSERT, UPDATE, DELETE queries are slower due to index maintenance
Too many indexes cause a slowdown in the database server
Confuses when the optimizer selects an execution strategy

II. Data Structure of Index
There are a lot of index types. However, in terms of structure, we have 2 most common: B-tree and Hash. So I will focus on these two types in this post.

1. B-tree index
This is a Balanced Tree (not a binary tree). Each node contains N values and pointers to the below nodes. Leaf nodes’ values are sorted and each leaf node contains a pointer to the original table.
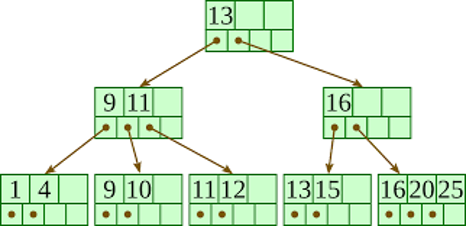
However, in modern databases such as MySQL and PostgreSQL, when we talk about B-tree, it actually is a B+ tree.
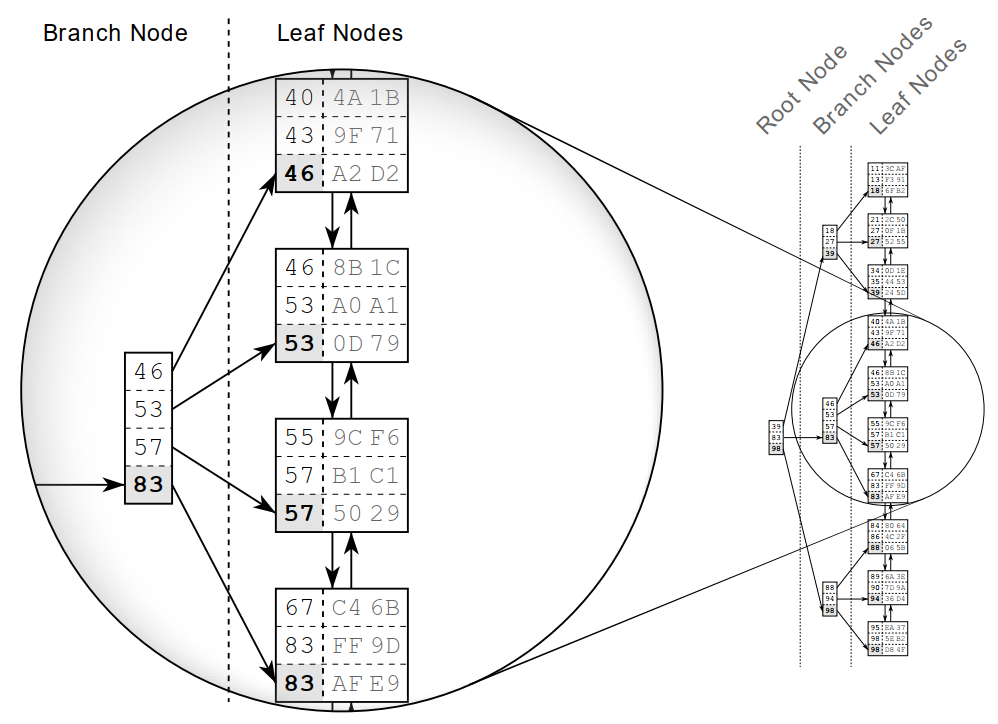
In B+ tree, leaf nodes are connected by a DOUBLE LINKED LIST. So it works more efficiently than B-tree in the case of range queries.
Each leaf node is stored in a block (page) – the smallest unit of the database. Each storage engine has a different block size.
E.g. MySQL (InnoDB) has a default block size of index = 16kB.
a. Searching on B+-tree
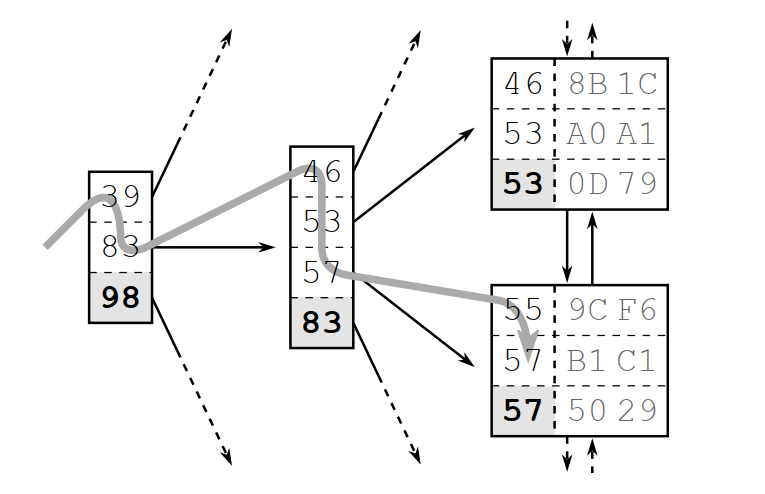
The below picture shows an index fragment to illustrate a search for the key "57". The tree traversal starts at the root node on the left-hand side. Each entry is processed in ascending order until a value is greater than or equal to (>=) the search term (57). Then the database follows the reference to the corresponding branch node and repeats the procedure until the tree traversal reaches a leaf node.
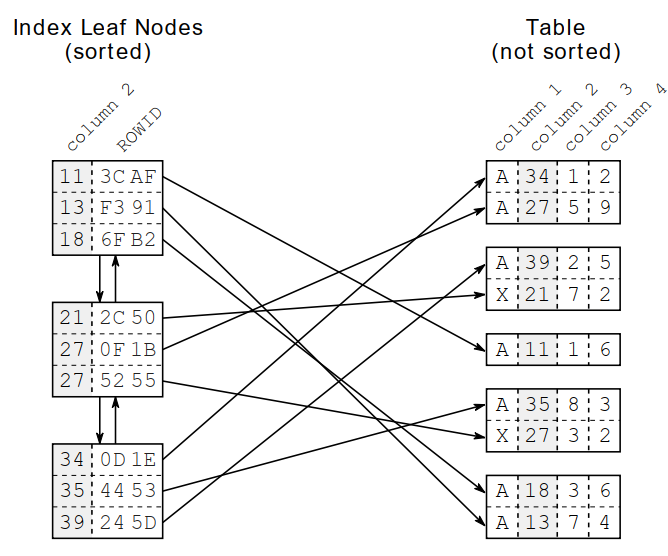
From leaf nodes, we have connections to the table data. Unlike the index, the table data is not sorted at all.
b. Supported Query Types
As I said, each database or storage engine supports different index types. So within the scope of this post, let's assume that we are working with MySQL + InnoDB engine.
we have a composite index of 2 columns employee_id and subsidiary_id.
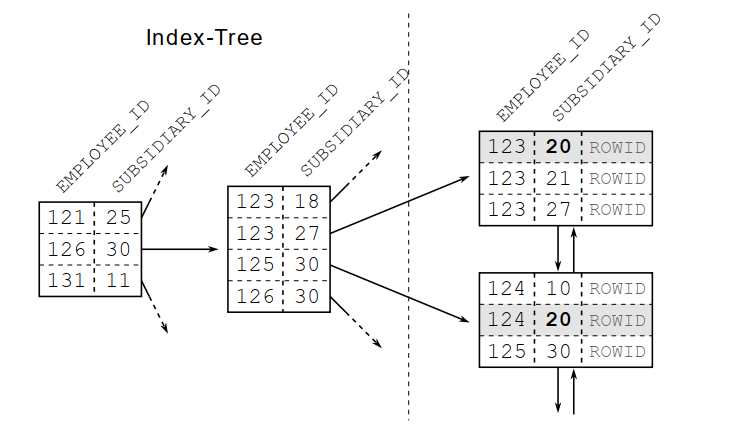
Match full value
Your database will use your index if you query by full values (=)
E.g.
WHERE employee_id = 1
WHERE employee_id = 123 and subsidiary_id = 20
Match leftmost prefix
Your database can use a composite index when searching with the leading (leftmost) columns. An index with three columns can be used when searching for the first column, when searching with the first two columns together, and when searching using all columns.
E.g.
OK: WHERE employee_id = 1
NOT OK: WHERE subsidiary_id = 20
Match range condition
Your database will use your index if you query by a range condition on the first column.
E.g.
OK: WHERE employee_id >= 123 and employee_id < 125
NOT OK: WHERE subsidiary_id > 20
Match equal in the left and range in the right column
E.g.
OK : WHERE employee_id = 123 and subsidiary_id > 20
NOT OK : WHERE employee_id > 123 and subsidiary_id = 20
\==> Only use index for employee_id search.
LIKE Operator (leftmost)
LIKE filters can only use the characters before the first wildcard during tree traversal. The remaining characters are just filter predicates that do not narrow the scanned index range.
The more selective the prefix before the first wildcard is, the smaller the scanned index range becomes.
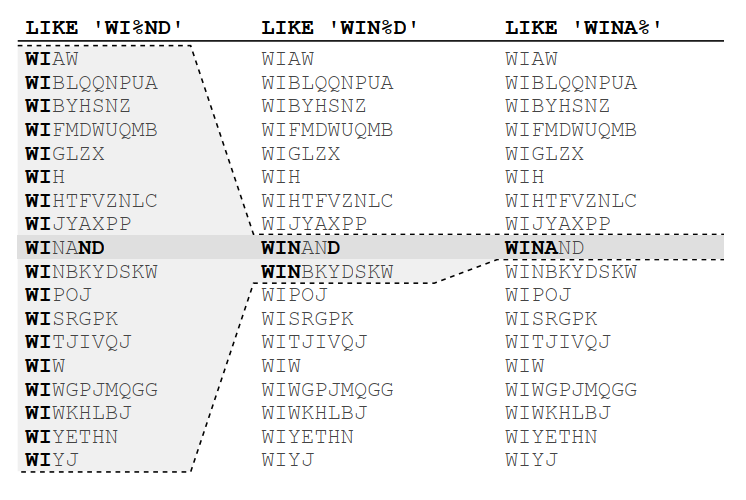
E.g.
OK: WHERE name LIKE ‘WI%ND’
NOT OK: WHERE name LIKE ‘%WIND%’
Covering Indexes
The index covers the entire query so it is also called a covering index. It prevents table access and runs pretty fast.
E.g. SELECT subsidiary_id FROM Employee WHERE employee_id > 123
Index Merge
There are queries where a single index cannot do a perfect job.
E.g. queries with two or more independent range conditions

You can of course accept the filter predicate and use a multi-column index nevertheless. That is the best solution in many cases anyway.
But what I want to say here is we have another option: two separate indexes, one for each column. Then the database must scan both indexes first and then combine the results.
Sorting/Group By
Your database will use your index in case of ordering or grouping because index data is sorted.
E.g. Select id, name FROM users ORDER BY id DESC limit 10
Function Indexes
You must use the same function of your query to create the index.
E.g.
Your query is:
SELECT id, fullname FROM users WHERE UPPER(fullname) = UPPER(‘Pham Duy Hieu’)
\=> You need to create an index with the UPPER function:
CREATE INDEX idx_name on users (UPPER(fullname))
c. Index with NULL values
When we create the index for Nullable columns, MySQL needs 1 byte to detect null/non-null values. Besides, optimizing queries (internal) in MySQL can be more challenging.
E.g. I have a users table
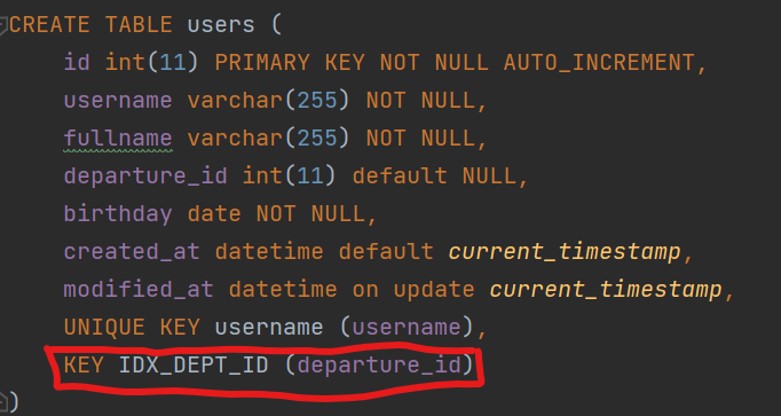
You can check the key length in Explain result:
explain select * from users where departure_id = 1;

You can see that departure_id is interger 4 bytes, right? However, the real key length is 5 bytes due to 1 byte for its length.
So you should set NOT NULL for your columns whenever you can. Even when you do need to store a “no value” in a table, you might not need to use NULL. Perhaps you can use zero, a special value, or an empty string instead.
However, don’t be too afraid of using NULL when you need to represent an unknown value. In some cases, it’s better to use NULL than a magical constant.
2. Hash Index
The index type is based on the Hashing technique to build a Hash Table and store indexed data. However, it is only supported by MySQL (Memory), Oracle and PostgreSQL.
If you are using MySQL InnoDB and you create a HASH index, InnoDB silently changes HASH to Btree.
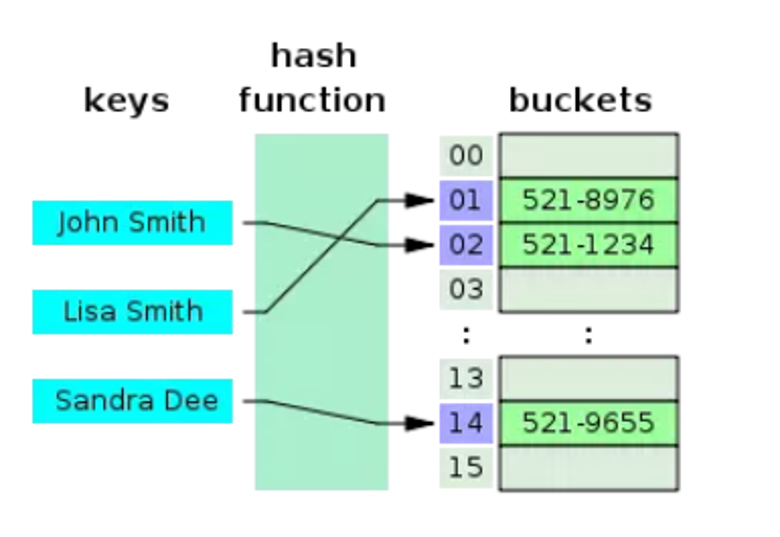
Here are some points of a hash index:
Good performance with "="
Don't support range queries (>, <, >=, <=) and sorting, group by
Hash Collision: should not be used for columns with many duplicated values
More space for hashing values (than B-tree)
We have just walked through the most common data structures for indexing and the supported query types accordingly. In the next post, I will share common indexing strategies allowing you to start practicing on your own. See youuuuu!
(continued)


