Database Indexing - Strategies for good indexes and high performance

In the last post, we walked through the basic concept, data structures, and supported query types of database indexes. Today, I will continue to share strategies for good indexes and high query performance.
Please bear in mind that you must practice these strategies to master them. Let's create your database and try with sample data such as Sakila,...
I. Choose The Right Column
Firstly, please list all queries for that table before deciding which indexes to create.
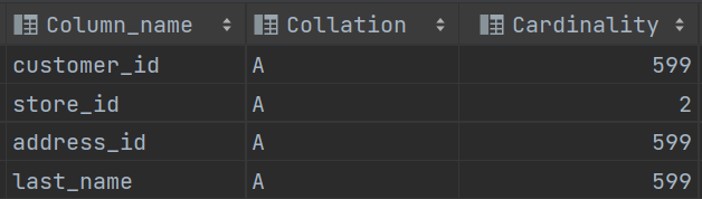
Secondly, don't create the index for columns with less distinct values (low cardinality).
E.g. status, action, is_active,...
You can check the cardinality figures by SHOW INDEX FROM + your tables
However, if the distribution of your ‘status’ column is unbalanced => Index still works if you only search by a value with lower distribution.
II. Create Prefix Index
If you need to create an index for a string/varchar column, I believe that you should create a prefix index:
Long enough to work efficiently
Short enough to reduce the index's storage
Example

Let's see the customer table with an index of the last_name column here and calculate the difference between the full-length index and prefix index of the first 6 chars:
Full length: key length = 45 * 4 + 1 (store length) = 181 bytes
Prefix index: key length = 6 * 4 + 1 (store length) = 25 bytes
Yes, the key length is 7 times larger.
How to find a good length
A good way to calculate a good prefix length is by computing the full column’s selectivity and trying to make the prefix’s selectivity close to that value.
E.g.: I have a city_demo table and I want to create an index for the city column.
- Step 1: we target a selectivity near 0.0312 as full-length selectivity.
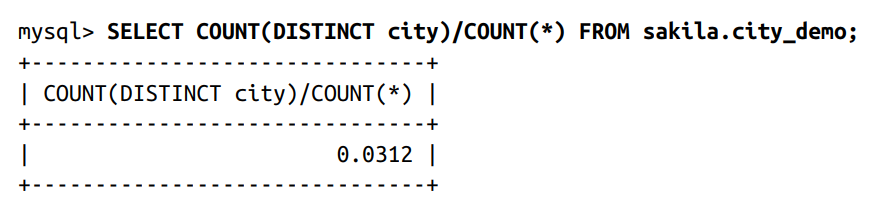
- Step 2: evaluate many different lengths in one query, which is useful on very large tables:

- Step 3: This query shows that seven characters are good enough for my prefix index.
III. Composite Index
Sometimes, you need to query by 2 columns in the same query. Please consider creating a composite index instead of an index for each column.
Individual indexes on lots of columns won’t help our database improve performance for most queries.
For example, MySQL can cope a little with such poorly indexed tables when it employs a strategy known as index merge, which permits a query to make limited use of multiple indexes from a single table to locate desired rows. It can use both indexes, scanning them simultaneously and merging the results.
However, the algorithm's buffering, sorting, and merging operations use lots of CPU and memory resources. So a composite index should be your first choice.
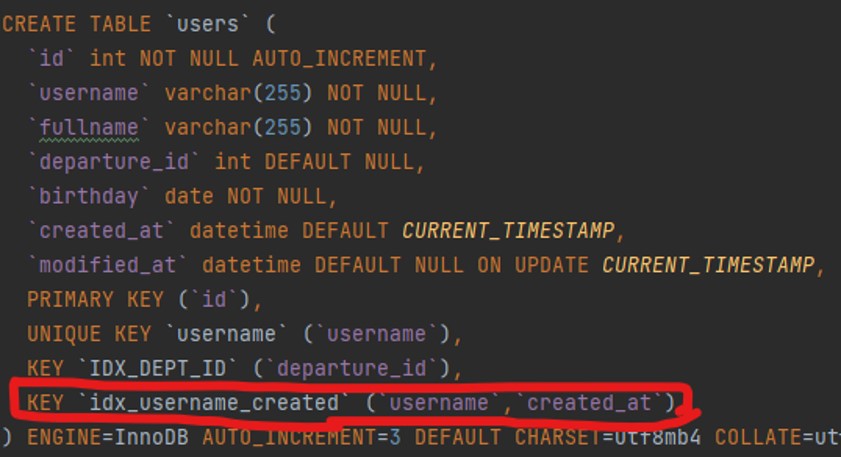
Another point is When you create a composite index for multiple columns, you can use that index in a query with the first column of the index.
E.g: The index of (username, created_at) can be used for both queries:
Select * from users where username=‘hieupd’ and create_at > ‘2022-01-01’
Select * from users where username=‘hieupd’
\==> No need an index for the username column only.
IV. Choose The Order for Composite Index
How?
Did you decide to create a composite index? OK good!
Now how about the order of columns?
I asked the question to at least 30 interviewees, and only one of them could answer.
The answer is:
Choose the column with higher selectivity as the first column (in most cases)
We can check the selectivity of columns by the query count distinct / count *.
Pay Attention!!!
When creating an index (A, B), no need to create an index only for A
Should put your range condition to the right of queries
In B-tree, if the range condition comes first in WHERE, the second column will not be used in that index
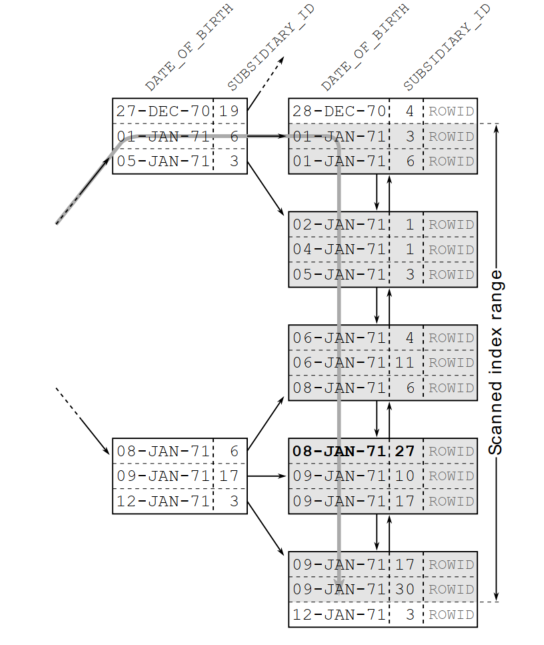
E.g.: In the above image, I have a composite B-tree index of (date_of_birth, subsidiary_id)
If I query by:
Select * from uses when date_of_birth between ’01-Jan-71’ and ’09-Jan-71’ and subsidiary_id = 27;\=> Our database only uses the index for the first range condition, and then scans on left nodes for the second condition (
subsidiary_id = 27) without index supports.
V. Clustered Index
Definition
Clustered indexes aren’t a separate type of index. Rather, they’re an approach to data storage.
When a table has a clustered index, its rows are actually stored in the index’s leaf pages.
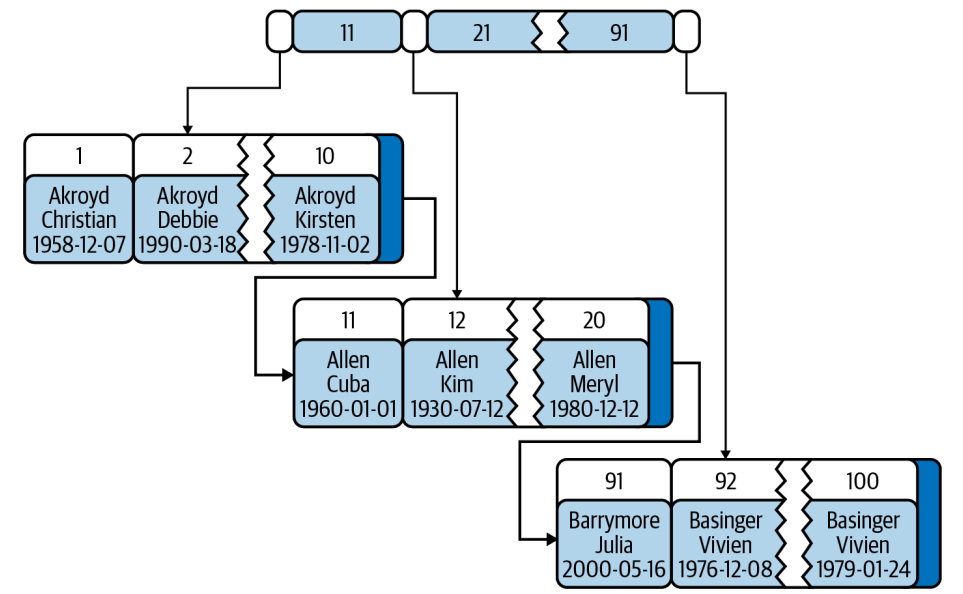
The leaf pages contain full rows, but the node pages contain only the indexed columns.
You can have only one clustered index per table because you can’t store the rows in two places at once.
Clustered indexes normally faster than non-clustered indexes
For instance, in MySQL InnoDB, the clustered index is our primary key. If you don’t define a primary key, InnoDB will try to use a unique non-nullable index instead.
Pay Attention!!!
In MySQL InnoDB, choosing the right PK is very important
Should not insert PK values randomly => need to reorder data, increase Disk I/O, disk fragmentation
VI. Covering Index
Indexes need to be designed for the whole query, not just the WHERE clause.
A Covering Index is:
An index that covers all data needed for a query (only B-tree can be used to cover indexes)
An index reduces Disk I/O and latency because no need to look up into disk.
So, please query only what you need, should not query redundant data (SELECT * FROM).
E.g.: In MySQL InnoDB, when you issue a query that is covered by an index (an index-covered query), you’ll see “Using index” in the Extra column in EXPLAIN:
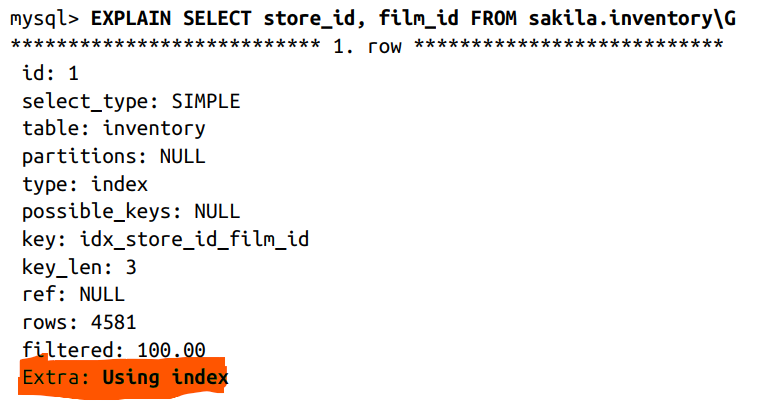
VII. Redundant and Duplicate Index
You should analyze your database indexes and remove duplicated and unused indexes. It helps our database to not need to maintain redundant indexes and reduce the impact for INSERT, UPDATE, and DELETE operations.
E.g.: In MySQL InnoDB, The best way to identify unused indexes is with performance_schema and sys:

Notice that if there is an index on (A, B), another index on (A) would be redundant because it is a prefix of the first index.
In most cases, you don’t want redundant indexes, and to avoid them you should extend existing indexes rather than add new ones. However, there are times when you’ll need redundant indexes for performance reasons. Extending an existing index might make it much larger and reduce performance for some queries.
VIII. Partial Index
So far we have only discussed which columns to add to an index. With partial (PostgreSQL) or filtered (SQL Server) indexes you can also specify the rows that are indexed.
A partial index is useful for commonly used where conditions that use constant values - like the status code in the following example:
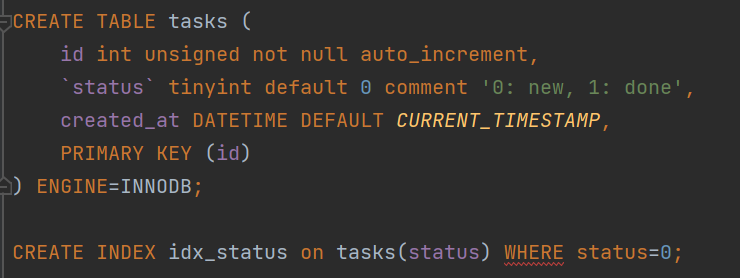
Queries like this are very common in queuing systems to fetch all unprocessed tasks.
Benefits
Specify the rows that are indexed
Reduce disk space and index size
Pay Attention!!!
Only Oracle, MongoDB, and PostgreSQL support
Very common in queuing systems
IX. Update Index Statistic
Over time, our data and indexes can become fragmented, which might reduce performance. So, we can consider running:
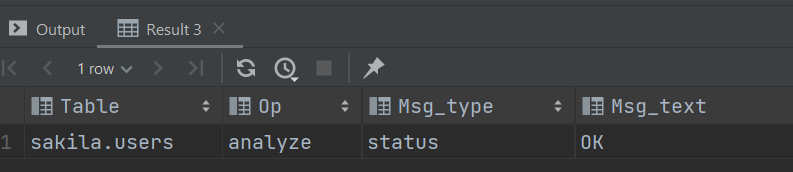
ANALYZE TABLE: calculates statistics for indexes
In MySQL, ANALYZE TABLE returns a result set with the columns shown in the following table.
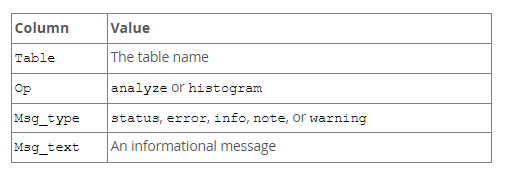
E.g.: ANALYZE TABLE users
OPTIMIZE TABLE: reorganizes the physical storage of table data and associated index data, to reduce storage space and improve I/O efficiency when accessing the table.
In MySQL, OPTIMIZE TABLE returns a result set with the columns shown in the following table.
For
InnoDBtables,OPTIMIZE TABLEis mapped toALTER TABLE ... FORCE, which rebuilds the table to update index statistics and free unused space in the clustered index.
Pay Attention!!!
Think twice before acting, especially on your Prod databases.
Need to be reviewed by database experts because it can cause downtime.

X. No Index
Last but not least, indexing is not a silver bullet. Sometimes, you get stuck improving your index performance. Please stay calm and think about alternative solutions rather than trying hard with indexing, such as:
Give up :D
Use suitable databases for your requirements
E.g.: To support aggregate queries, please use OLAP databases instead of OLTPs.
Build temp tables for heavy queries
Partition your tables, and archive data frequently (based on data retention)
Combine multiple databases
Apply CDC (Change Data Capture) to replicate data and scale your read performance.
XI. Conclusion
We just covered 10 strategies for effective indexing and achieving high query performance. I hope this article is useful for anyone working with indexes.
Bear in mind that each database and its storage engines have different index implementations and support different index types. Therefore, be mindful of the database type, storage engine, and version you are using before creating/optimizing your indexes.


