High Performance in MySQL - Part 2

Today I will continue to share my note about 3 topics: Replication, Table partitioning, and Scaling with MySQL.
You could read Part 1 here: High Performance in MySQL - Part 1
Notes: if you have read High Performance in MySQL book, you could realize that my series is only a note I rewrite from this book. My main goal is that I won't forget what I've learned, and can look it up online whenever I need it.
I. Replication
Replication lets you configure one or more servers as replicas of a master server, keeping their data synchronized with the source copy.
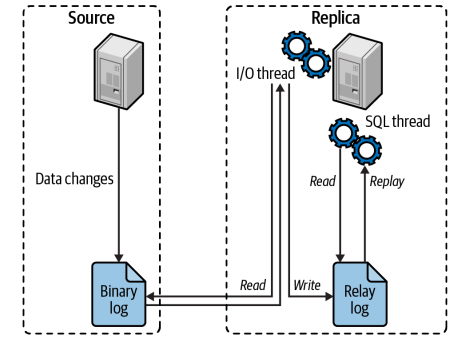
How Replication works
At a high level, replication is a simple three-part process:
The source records changes to its data in its binary log as “binary log events.”
The replica copies the source’s binary log events to its local relay log.
The replica replays the events in the relay log, applying the changes to its own data.
Benefits
Data distribution: useful for maintaining a copy of your data in a geographically distant location, such as a different data center or cloud region
Scaling read traffic: distribute read queries across several servers, which works very well for read-intensive applications (need to setup LB)
Backups: a valuable technique for helping with backups. However, a replica is neither a backup nor a substitute for backups.
Analytics and Reporting: Using a dedicated replica for reporting/analytics (online analytical processing, or OLAP) queries
High availability and failover: avoid making MySQL a single point of failure in your application
Testing MySQL upgrades: common practice to set up a replica with an upgraded MySQL version and use it to ensure that your queries work as expected before upgrading every instance.
Replication Problems and Solutions
Binary Logs Corrupted on the Source: rebuild your replicas
Non-unique Server IDs: accidentally configure two replicas with the same server ID => be careful when setting up your replicas
Undefined Server IDs: will not let you start the replica
Missing Temporary Tables: use row-based replication | name your temporary tables consistently (prefix with temporary_, for example) and use replication rules to skip replicating them entirely
Not Replicating All Updates: misuse SET SQL_LOG_BIN = 0 or don’t understand the replication filtering rules, your replica might not execute some updates that have taken place on the source
Replication Lag:
Multithreaded replication
Use sharding: scale reads with replicas, scale writes with sharding
Turn off sync bin log on replicas (when sharding is not a viable option because of effort or design issues)
Keep it simple. Don’t do anything fancy, such as using replication rings or replication filters, unless you really need to.
II. Table Partitioning
Table Partitioning is the way a MySQL database splits its actual data down into separate tables, but still gets treated as a single table by the SQL layer
Partitioning Rules
- must add the partition key into the primary key
Ex: the primary key must include “created” column
CREATE TABLE userslogs (
username VARCHAR(20) NOT NULL,
logdata BLOB NOT NULL,
created DATETIME NOT NULL,
PRIMARY KEY(username, created)
)
PARTITION BY RANGE( YEAR(created) )(
PARTITION from_2013_or_less VALUES LESS THAN (2014),
PARTITION from_2014 VALUES LESS THAN (2015),
PARTITION from_2015 VALUES LESS THAN (2016),
PARTITION from_2016_and_up VALUES LESS THAN MAXVALUE
the table itself becomes a virtual concept. The partitions hold the data and any indexes are built on the data in the partitions.
MySQL supports horizontal partitioning but not vertical
Partition types:
Range: it is great because you have groups of known IDs in each table, and it helps range queries.
Hash: “load balances” the table, and allows you to write to partitions more concurrently. This makes range queries on the partition key a bad idea.
Benefits
Deletion: quickly delete data that is no longer needed
Storage: possible to store more data in one table than can be held on a single disk or file system partition
Performance: Query data faster when only accessing a smaller volume of data (could apply partition pruning)
III. Scaling MySQL
Scaling is the system’s ability to support growing traffic
Read-Bound Workloads
When adding more application nodes to scale the clients serving requests leads to some database issues:
High CPU: means the server is spending all of its time processing queries. The higher CPU utilization gets, the more latency you will see in queries.
Heavy disk read IOPS or throughput: indicating that you are going to disk very often or for large numbers of rows read from disk
\==> adding indexes, optimizing queries, and caching data you can cache
Write-Bound Workloads
There are some examples of write-bound workloads:
Peak e-commerce season and sales are growing, along with the number of orders to track.
Signups are growing exponentially (Ex: ChatGPT reaches 100 million users 2 months after launch)
All of these are business use cases that lead to exponentially more database writes that you now have to scale.
\==> scale up (add more RAM, CPU and disk) or scale out (functional sharding)
1.Scaling Read
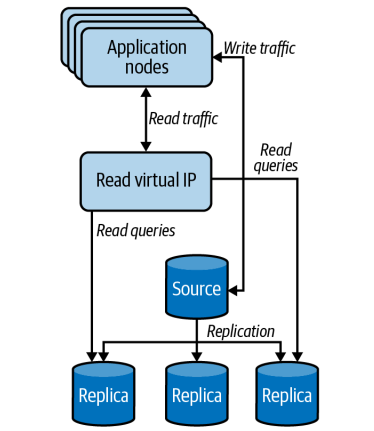
Use Replica Read Pools
A very common way to manage these read pools is to use a load balancer (HAProxy, Nginx) to run a virtual IP that acts as an intermediary for all traffic meant to go to the read replicas
2.Scaling Write with Sharding
Sharding means splitting your data into different, smaller database clusters so that you can execute more writes on more source hosts at the same time.
Do not split based on the structure of the engineering team. That will always change at some point. Do split tables based on business function
Most applications shard only the data that needs sharding—typically, the parts of the data set that will grow very large. And not just the data that is growing rapidly but also the data that logically belongs with it and will regularly be queried at the same time (partitioning)
Do not shy away from tackling spots where separate business concerns have been intermingled in the data and you need to advocate for not just data separation but also application refactoring and introducing API access across those boundaries.
Choosing a Partitioning Scheme
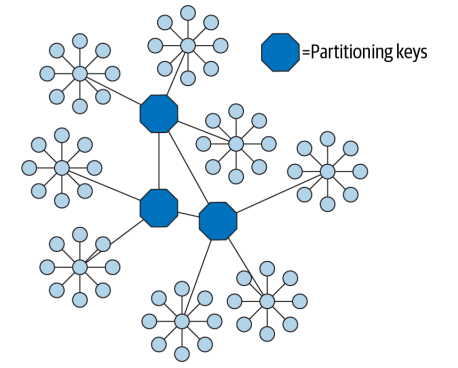
A good partitioning key is usually the primary key of a very important entity in the database. These keys determine the unit of sharding. For example, if you partition your data by a user ID or a client ID, the unit of sharding is the user or client.
Diagram your data model with an entity-relationship diagram or an equivalent tool that shows all the entities and their relationships. Try to lay out the diagram so that the related entities are close together.
Consider your application’s queries as well. Even if two entities are related in some way, if you seldom or never join on the relationship, you can break the relationship to implement the sharding.
Choosing a partitioning key that lets you avoid cross-shard queries as much as possible but also makes shards small enough that you won’t have problems with disproportionately large chunks of data
Querying across Shards
Most sharded applications have at least some queries that need to aggregate or join data from multiple shards (for reports)
Strive to make your queries as simple as possible and contained within one shard.
For those cases where some cross-shard aggregation is needed, we recommend you make that part of the application logic.
Cross-shard queries can also benefit from summary tables. You can build them by traversing all the shards and storing the results redundantly on each shard when they’re complete. If duplicating the data on each shard is too wasteful, you can consolidate the summary tables onto another data store so they’re stored only once.
IV. Summary
Optimizing and scaling MySQL is a journey. Before you dive into scalability bottlenecks, make sure you’ve optimized your queries, checked your indexes, and have a solid configuration for MySQL.
Once optimized, focus on determining whether you are read-bound or write-bound, and then consider what strategies work best to solve any immediate issues.
For read-bound workloads, our recommendation is to move to read pools unless replication lag is an impossible problem to overcome. If lag is an issue or if your problem is write-bound, you need to consider sharding as your next step.
That's all about MySQL I know so far. I hope it could help you to consolidate your knowledge and give you some ideas to optimize your MySQL.


